
I sketched a free-body diagram of a hot glue gun’s stick-advance mechanism in an attempt to formalize its action. (I was also surprised to see hot glue used to secure wires inside the hot glue gun… a textbook chicken / egg paradox.)
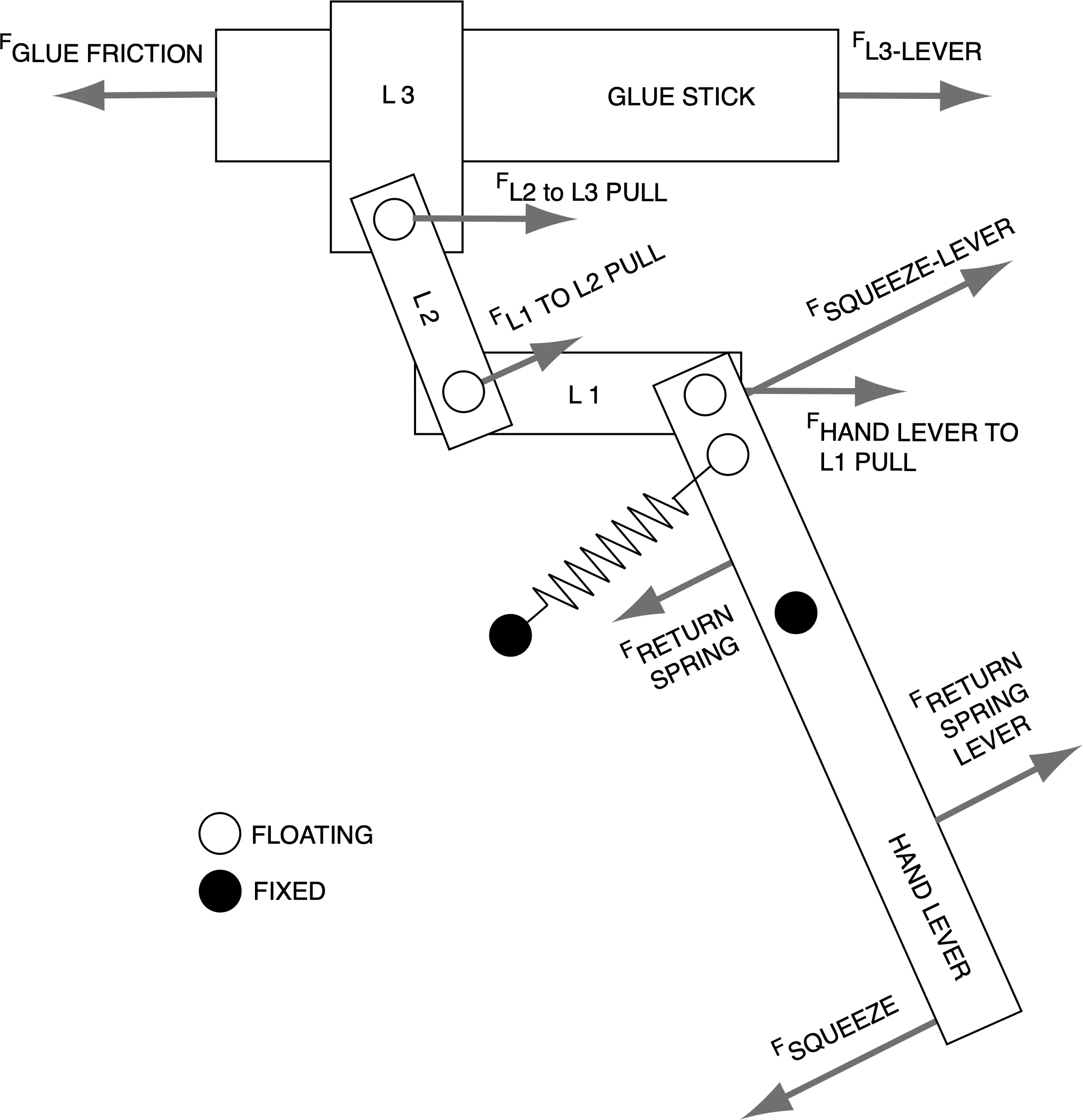
I sketched a free-body diagram of a hot glue gun’s stick-advance mechanism in an attempt to formalize its action. (I was also surprised to see hot glue used to secure wires inside the hot glue gun… a textbook chicken / egg paradox.)
Can a machine accumulate enough information about your patterns of communication to create an effective digital doppelgänger?
Could we use the data left behind on Google’s servers and our own hard disks to effectively replace ourselves with an artificial intelligence born and bred of our online conversations and quirks? What might it be like to have a conversation with a past representation of ourselves, what would a hypothetical exchange between two digitally-reconstructed individuals look like?
Michael Edgcumbe and I approached these questions with Caprica, our rough attempt to commit to code some of the ideas of digital reincarnation put forth in the (reportedly mediocre) eponymous television series.
Both Michael and I have managed to retain a good portion of our instant messenger chat logs. My archives represent just over a half-million lines of conversation logged from about 2001 to 2004. Michael’s are a bit more recent, and weigh in at 34,000 lines. So data is in relative abundance.
The goal was to build an autonomous chat bot that would draw from the content of our logs to construct an infinite stream of back-and-forth conversation between our younger selves. Ideally, these conversations should be reasonably cogent and reflect whatever personality / themes we left behind in our logs.
Our initial approach to an algorithm was simple — the entire chat log can be considered a kind of question / answer training set. There’s a bit of latent intelligence built right into the log, since it literally documents how you responded to a wide range of queries. By finding which line in the log is the closest match to a given query, we should be able to walk forward a few lines and retrieve a reasonable response. This turns the problem into one of sentence similarity and avoids the issue of extracting and classifying meaning from the logs.
There are some peculiarities about instant messenger conversations which needed to be considered:
With these points in mind, we tried a number of techniques for ranking similarity between a query string and lines of logged conversation. First, we wanted to increase the opportunities for a match between the query and the log, so we used lemmatization / synonym lookup to expand the query.
For example, for the query how about the weather each word is expanded into a list of synonymous terms:
[
['how'],
['about', 'astir', 'approximately', 'close_to', 'just_about', 'some', 'roughly', 'more_or_less', 'around', 'or_so', 'almost', 'most', 'nearly', 'near', 'nigh', 'virtually', 'well-nigh'],
['the'],
['weather', 'weather_condition', 'conditions', 'atmospheric_condition', 'endure', 'brave', 'brave_out', 'upwind']
]From there, the chat log is searched for lines containing these synonyms — each word match improves the score of a particular line, which means its more likely to wind up as the best match to the query.
Other methods attempted include turning the logs into bigrams, to give a bit more weight to pairs of words used in context — this proved too slow to run in real time, we would need to set up a cache or database of bigrams for each log to use this approach in the future. (It’s currently scrapped from the working implementation.)
We also attempted to ignore line breaks in the logs and instead treat each stream of replies from one individual as a single chunk. This left us with unnaturally long-winded responses, slower searches (since the queries were much longer) and less of a quality improvement than we expected. (Also scrapped from the working implementation.)
Finally, our algorithm handles some basic house keeping: A response gets flagged after it’s used, so that conversations won’t repeat themselves. Response scores are also normalized based on length, so that longer lines (with more potential word matches) don’t dominate the conversation. It also manages the eternal conversational bounce between each log: After a response is generated, that response becomes the query to the other log… ad infinitum until every single line is used.
The source code is available on GitHub. The caprica_3_presented.py file represents the most recent working implementation.
Here’s an excerpt of a hypothetical conversation between my adolescent self and Michael:
Edgwired: what are we lying about? obrigado: the royal you Edgwired: we had to transfer them as files rather than as music obrigado: hah Edgwired: heh obrigado: wtf? Edgwired: music is portable obrigado: J.R. Rodale Edgwired: plus obrigado: additionaly Edgwired: cool to hang out obrigado: all this time coco Edgwired: this is what i’m leaning towards obrigado: i have assumed Edgwired: LOL obrigado: haha Edgwired: what monitor? obrigado: right Edgwired: that one is pretty good obrigado: that the version of remind me Edgwired: fuck it obrigado: actually it is Edgwired: serious
The full text is also available.
Even with our crude implementation, the generated conversations are at least moderately interesting. Humans are quite good at finding patterns and extrapolating meaning where there is actually very little of either, and I think this helps mask the mediocrity of the algorithm.
We have a number of ideas for improvements that didn’t make it into the first cut.
We considered Stemming the logs to increase the number of matches. However, the search code we’re using at the moment allows for partial word matches, so I’m not sure how much we would gain from this step.
Another major issue is that the log data requires a massive amount of clean-up before it’s ready for use. Ideally, we would have a program that would automatically aggregate a user’s chat (or email, or twitter, etc.) data without them needing to dig up their logs from the depths of the file system and run a bunch of finicky clean-up routines to get the data ready for use. Michael and I spent a huge amount of time dealing with character encoding issues and generally restructuring the log data so that it was consistent for both of us. Writing a reliable, hands-off parser would be a lot of work, but it would be consistent with the goals of the project: to provide access to an interactive, digital representation of oneself.
Python starts to show its slowness when you’re handling many thousands of lines of strings… for efficiency’s sake, the logs would benefit from migration to a database system.
And most importantly, the sentence similarity approach is deeply naïve. There’s a lot more to the reconstruction process than finding word matches, and to improve the results we will really need a way to extract and tag actual data from the logs. We will need some way to identify major themes and then weave them together into more convincing conversation.
Google’s automatic search completion give an instant zeitgeist from just a few words of input. Here’s an example of it at work:

A universal auto-complete function would be a useless and wonderful thing to have, and right now I think Google’s search completion is as close as we can get. I’m interested in what would happen if a piece of text was forced to conform with Google’s platonic search query, essentially handing over final editorial authority the their algorithm — which in itself is just a representation of grooves worn into the search engine by millions of people searching for exactly the same thing.
Google sometimes imposes their assistance by placing a link at the top of search results suggesting “did you mean something?” This officious interjection is often creepily right — why yes, I did mean something.
Hence my proposed poetic form: You Mean. This form takes Google’s help a step further by forcing a given string through the suggestion algorithm and reconstructing output consisting entirely of suggestions.
For example, the paragraph above becomes the following:
Henceforth myspace proposed health care bill poetic forms you mean the world to me this form is submitted in connection with an application for takeshi kaneshiro google scholar help a reporter out step further or farther byu forcing amaryllis longest palindrome in a given string through the looking glass suggestion algorithms andkon reconstructing history output devices consisting essentially of entirely pets office depot suggestions lyrics.
First, I needed programmatic access to Google’s suggestions. Google itself was helpful enough to point me to this gentle hack of their toolbar code — a URL that you can hit for an XML list of suggestions for a given query. Handy.
Next, there was the issue of how to atomize input text. This proved a bit trickier, since judgments would have to be made as to how much of a line should be fed through the algorithm at a time. Initially, I tried sending words in individually. This was helpful in creating repetitive structures in the output, but I thought it was loosing to much of the source text’s content.
So I implemented a recursive algorithm that takes the full text of a line, and then tests to see if there are suggestions for it. If there are suggestions, it declares success. If not, it pops a word off the end up the sentence, and tries to find a suggestion for the new, shorter line. It continues to pop words until it finds a suggestion, and then will return to the rest of the sentence and go through the same process of shortening until a suggestion is found. Eventually, a whole line is digested this way. It unfairly weights the beginning of the line (since it’s tested first) but it seemed like a reasonable compromise between performance (the http queries take some time) and content retention.
With some extra print statements, processing looks like this — showing the recursive approach to suggested-sentence generation:
You say: showing the recursive approach
trying: showing the recursive approach
no suggestions
trying: showing the recursive
no suggestions
trying: showing the
suggestion: shown thesaurus
trying: recursive approach
no suggestions
trying: recursive
suggestion: recursive formula
trying: approach
suggestion: approach plates
You mean: shown thesaurus recursive formula approach plates
Occasionally, Google gets stumped on a single word and runs out of suggestions. (“Pluckiest”, for example.) In these cases, the algorithm relents and lets the original word through. It’s conceivable that an entire body of text could elude suggestions in this way, if the words were far enough from the online vernacular.
An interesting behavior emerges in canonical texts. Partial lines will be automatically completed with the original text, which gives the text a tendency to repeat itself.
For example, here’s Frost:
whose woods these are i think i know his house is in the village though
his house is in the village though thought for the day
he will not see me stopping here to watch his woods fill up with snow
to watch his woods fill up with snow snowshoe mountain
my little horse must think it queer to stop without a farmhouse near
to stop without a farmhouse near near death experiences
between the woods and frozen lake the darkest evening of the year
the darkest evening of the year by dean koontz
he gives his harness bells a shake to ask if there is some mistake
to ask in spanish if there is something lyrics mistake quotes
the only other sound’s the sweep sounds the same spelled differently sweepstakes
of easy wind and downy flake flake lyrics
the woods are lovely dark and deep poem
but i have promises to keep and miles to go before i sleep
and miles to go before i sleep meaning
and miles to go before i sleep meaning
The code is designed to work in two possible configurations. You can either pass it text via standard input, which it will suggestify and spit back out. Or, you can run it with the argument “interactive”, which will bring up a prompt for you to experiment quickly with different suggested text transformations.
import sys
import urllib
from xml.dom import minidom
import string
# set to true for more output
debug = 0
def strip_punctuation(s):
return s.translate(string.maketrans("",""), string.punctuation)
# returns a list of google suggestions
# store them in a dictionary for basic caching... then when parsing the text
# fetch the suggestion from google only if we need to
suggestion_cache = dict();
def fetch_suggestions(query):
if query in suggestion_cache:
return suggestion_cache[query]
# here's the suggestion "API"
# google.com/complete/search?output=toolbar&q=microsoft
# adding a trailing space prevents partial matches
# how to handle multi-word? find the largest possible suggestions
query_string = urllib.urlencode({"output" : "toolbar", "q" : query})
# returns some xml
suggestion_request = urllib.urlopen("http://www.google.com/complete/search?" + query_string)
suggestions = list();
# handle the odd xml glitch from google
try:
suggestion_xml = minidom.parse(suggestion_request)
# let's extract the suggestions (throw them in a list)
for suggestion in suggestion_xml.getElementsByTagName("suggestion"):
suggestions.append(suggestion.attributes["data"].value)
suggestion_cache[query] = suggestions;
except:
pass
suggestion_request.close()
return suggestions
# glues together a list of words into a sentence based on start and end indexes
def partial_sentence(word_list, start, end):
if len(word_list) >= end:
sentence = str()
for i in range(start, end):
sentence = sentence + word_list[i] + " "
return sentence.strip()
else:
return "partial sentence length error"
# takes a line and recursively returns google's suggestion
def suggestify_line(line):
output_text = ""
words = line.lower().strip().split(" ")
if len(words) > 1:
end_index = len(words)
start_index = 0
suggested_line = ""
remaining_words = len(words)
# try to suggest based on as much of the original line as possible, then
# walk left to try for matches on increasingly atomic fragments
while remaining_words > 0:
query = partial_sentence(words, start_index, end_index)
suggestions = fetch_suggestions(query)
if debug: print "trying: " + query
if suggestions:
if debug: print "suggestion: " + suggestions[0]
output_text += suggestions[0] + " "
remaining_words = len(words) - end_index
start_index = end_index;
end_index = len(words)
else:
# else try a shorter query length
if debug: print "no suggestions"
# if we're at the end, relent and return original word
if (end_index - start_index) == 1:
if debug: print "no suggestions, using: " + words[start_index]
output_text += words[start_index] + " "
remaining_words = len(words) - end_index
start_index = end_index;
end_index = len(words)
else:
end_index -= 1
# handle single word lines
elif len(words) == 1:
if debug: print "trying: " + words[0]
suggestions = fetch_suggestions(words[0])
if suggestions:
if debug: print "suggestion: " + suggestions[0]
output_text += suggestions[0] + " ";
else:
if debug: print "defeat"
# defeat, you get to use the word you wanted
if debug: print words[0]
output_text += words[0] + " ";
output_text.strip()
return output_text
# are we in interactive mode?
if len(sys.argv) <= 1:
# Grab a file from standard input, dump it in a string.
# source_text = sys.stdin.readlines()
source_text = open("frost.txt").readlines()
#source_text = "His house is in the village though"
output_text = ""
for line in source_text:
output_text += suggestify_line(strip_punctuation(line))
output_text += "\n"
print output_text
elif sys.argv[1] == "interactive":
while 1:
resp = raw_input("You say: ")
print "You mean: " + suggestify_line(strip_punctuation(resp)) + "\n"
if resp == "exit":
breakimport sys
import urllib
from xml.dom import minidom
import string
# set to true for more output
debug = 0
def strip_punctuation(s):
return s.translate(string.maketrans("",""), string.punctuation)
# returns a list of google suggestions
# store them in a dictionary for basic caching... then when parsing the text
# fetch the suggestion from google only if we need to
suggestion_cache = dict();
def fetch_suggestions(query):
if query in suggestion_cache:
return suggestion_cache[query]
# here's the suggestion "API"
# google.com/complete/search?output=toolbar&q=microsoft
# adding a trailing space prevents partial matches
# how to handle multi-word? find the largest possible suggestions
query_string = urllib.urlencode({"output" : "toolbar", "q" : query})
# returns some xml
suggestion_request = urllib.urlopen("http://www.google.com/complete/search?" + query_string)
suggestions = list();
# handle the odd xml glitch from google
try:
suggestion_xml = minidom.parse(suggestion_request)
# let's extract the suggestions (throw them in a list)
for suggestion in suggestion_xml.getElementsByTagName("suggestion"):
suggestions.append(suggestion.attributes["data"].value)
suggestion_cache[query] = suggestions;
except:
pass
suggestion_request.close()
return suggestions
# glues together a list of words into a sentence based on start and end indexes
def partial_sentence(word_list, start, end):
if len(word_list) >= end:
sentence = str()
for i in range(start, end):
sentence = sentence + word_list[i] + " "
return sentence.strip()
else:
return "partial sentence length error"
# takes a line and recursively returns google's suggestion
def suggestify_line(line):
output_text = ""
words = line.lower().strip().split(" ")
if len(words) > 1:
end_index = len(words)
start_index = 0
suggested_line = ""
remaining_words = len(words)
# try to suggest based on as much of the original line as possible, then
# walk left to try for matches on increasingly atomic fragments
while remaining_words > 0:
query = partial_sentence(words, start_index, end_index)
suggestions = fetch_suggestions(query)
if debug: print "trying: " + query
if suggestions:
if debug: print "suggestion: " + suggestions[0]
output_text += suggestions[0] + " "
remaining_words = len(words) - end_index
start_index = end_index;
end_index = len(words)
else:
# else try a shorter query length
if debug: print "no suggestions"
# if we're at the end, relent and return original word
if (end_index - start_index) == 1:
if debug: print "no suggestions, using: " + words[start_index]
output_text += words[start_index] + " "
remaining_words = len(words) - end_index
start_index = end_index;
end_index = len(words)
else:
end_index -= 1
# handle single word lines
elif len(words) == 1:
if debug: print "trying: " + words[0]
suggestions = fetch_suggestions(words[0])
if suggestions:
if debug: print "suggestion: " + suggestions[0]
output_text += suggestions[0] + " ";
else:
if debug: print "defeat"
# defeat, you get to use the word you wanted
if debug: print words[0]
output_text += words[0] + " ";
output_text.strip()
return output_text
# are we in interactive mode?
if len(sys.argv) <= 1:
# Grab a file from standard input, dump it in a string.
# source_text = sys.stdin.readlines()
source_text = open("frost.txt").readlines()
#source_text = "His house is in the village though"
output_text = ""
for line in source_text:
output_text += suggestify_line(strip_punctuation(line))
output_text += "\n"
print output_text
elif sys.argv[1] == "interactive":
while 1:
resp = raw_input("You say: ")
print "You mean: " + suggestify_line(strip_punctuation(resp)) + "\n"
if resp == "exit":
breakThe (slightly anemic) start of an homage to the most beloved software of my youth, the original KidPix.
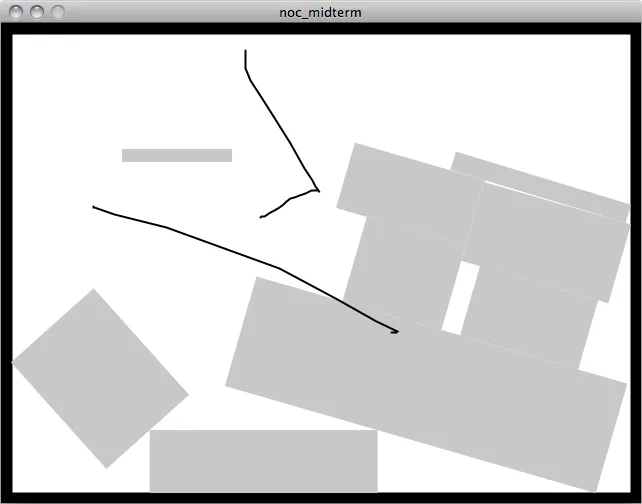
Based heavily on the PBox2D examples, this sketch lets you draw objects with physical properties onto a canvas.

Some of the most interesting mechanical solutions seem to have emerged from the transition period between manual and automated means of production — the process of adapting tasks long performed by hand to operate under machine power for the first time.
The initial iterations of the adaptation process usually result in endearingly anthropomorphic machines, since the process of abstracting human motions out of the process isn’t yet complete. (Examples include electric typewriters, sewing machines, automated assembly lines, etc.)
I’m interested in working through this process of converting hand power to mechanical power myself. A Dymo tapewriter represents an unlikely but possibly satisfying platform to turn into an automatic, electronic device.
I’m also interested in unintended and unknown physical consequences for actions taken online. The stream of new tag data on sites like Flickr could provide interesting source text, and would force the idea of a tag into the physical world --- e.g. here’s a machine that involuntarily spits out sticky pieces of tape with letters on them that could, conceivably, tag real-world objects.
Thus, the TagBot. A mechanized, automatic Dymo tapewriter which scrapes new tag data from Flickr in real time, and generates labels accordingly.
A slightly more ambitious variant could be built with mobility in mind — you could position it somewhere in the city, and it would spit out tags from photographs taken in the vicinity.
Mechanically, several factors need to be accounted for:
Code and control will require the following: